Text analysis tutorial created by Dr. Joanna Mundy at the Emory Center for Digital Scholarship.
Bertha Clay is a pen name originally used by Charlotte Mary Brame, an author of genre fiction, who lived from 1836 to 1884. The pen name, however, lived on considerably, and was picked up as a “house name” for authors by Street & Smith among other publishers, and used variously by authors, many of them male.[1] After the death of Brame, Street & Smith often had authors take and reprint material taken from other publishers, reworked into the pattern of a Bertha Clay novel. Among these authors was John Coryell, author of the Nick Carter novels, who published many novels under the name Bertha Clay close the time of her death, when some of her novels were still being published posthumously.[2]
In the Women Writer’s Collection of Genre Fiction, we have one novel, Married for her Beauty or, A Bitter Atonement, which is listed as written by Bertha Clay, as a pen name for Charlotte Brame (1836-1884). However, we have three other novels written by Bertha Clay in our collection: Beyond Atonement, Repented at Leisure, and New Love or Old. The records on who wrote which Bertha Clay novel are not fully complete, and difficult to track down. This situation provides the opportunity for us to examine these works through text mining to see if we can determine the authors by means of their word choice.
Part One: Preparing the Corpus
First we had to gather a collection of works that include our four Bertha Clay novels, and other novels by Bertha Clay, by John Coryell, and by other authors who published as Bertha Clay. We gathered 37 works by this author selection.
We have also included four works by Mrs. Margaret Wolfe Hamilton Hungerford, called The Duchess, to act as controls. These works, known to also be romance genre fiction by a different single author, provide a contrast.
Now that we have our corpus, which you can download here, we open RStudio. For this corpus we cleaned and removed only the numbers and punctuation out of the text. The 100 most common words are typically the words that most exhibit authorship, words such as and, the, he, and she, so it is important for this study not to remove stopwords.
When you start RStudio, it is a good idea for text mining to go ahead and load the primary libraries. We will not use Mallet for this tutorial, but the statement below prepares your RStudio session, should you want to use it on this corpus also.
Now we are booted and ready to go. The first step to process the corpus, and remove numbers and punctuation, particularly important when there may be OCR errors in your text sample, is to import the corpus with tm.
> whoisclay <- VCorpus(DirSource("/path/to/clay_corpus/"))
This creates a VCorpus that we can manipulate using the TM library. Then we will want to remove the punctuation, but not all punctuation is the same. First, let’s remove contractions! For instance, you do not want to replace the ‘ in let’s with a space, because that would leave you with two words “let” “s”, and the “s” would throw off your study. Let’s create a statement to remove ‘ and replace it with an empty string “”, so that let’s becomes “lets”. We can use content_transformer to do this.
> contractaway <- content_transformer(function(x, pattern) gsub("'", "", x))
Now we can map that function with the TM library to our corpus, and remove those contractions.
> claydocs1 <- tm_map(whoisclay, contractaway)
Now that the contractions are gone we can remove the rest of the punctuation and replace it with a space “ “. Then we will again map that with the TM library to our corpus, but remember to use the corpus that has the contractions removed.
> puncttoSpace <- content_transformer(function(x, pattern) gsub("[[:punct:]]+", " ", x))
> claydocs2 <- tm_map(claydocs1, puncttoSpace)
Now we want to convert all the text to lowercase. It is important to make this change so that “He” from the beginning a sentence and “he” from the middle do not get processed as separate words. They will all become “he” and be processed together. We can again map this function using the TM package. Make sure to use the right corpus!
> claydocs3 <- tm_map(claydocs2, content_transformer(tolower))
Then will remove the numbers with the TM package, so that we are only processing the words.
> claydocs4 <- tm_map(docsforwgfm1, removeNumbers)
This has created a VCorpus that has processed out your numbers, punctuation, and replaced uppercase text! However, we will want to use this corpus as a folder of text files, not just as a VCorpus for this study. In order to convert a VCorpus back into a clean folder corpus, we need to take a few steps.
First, import the index file to RStudio. This will allow you to name the files as they are exported.
> index <- read.csv(file = "/path/to/Clay_index.csv")
Now create a folder called clay_clean_corpus. We will use the writeCorpus corpus. The writeCorpus function takes a VCorpus, a path to the folder for the written corpus, and an index file to use to name the output files. We have our VCorpus claydocs4, our path/to/clay_clean_docs, and the index that you just imported. You will have to add [[1]] to the index in the writeCorpus function, so that it only uses the first column of the index file to name the output txt files.
> writeCorpus(claydocs4, path = "/path/to/clay_clean_docs/", filenames = index[[1]])
We have a clean folder of docs to process!
Part Two: Stylo
We are going to start processing this corpus using the package Stylo. Install the package if you do not already have it and load it.
> library(stylo)
Loading the Stylo library will also open XQuartz beside Rstudio. Stylo requires a specific folder structure to process a corpus. Create a new project folder claystylo/ for this project, and copy your clay_clean_docs/ folder and its contents inside. Rename the copy of clay_clean_docs/ to corpus/. Your new folder structure should look like /path/to/claystylo/corpus/.
Once you have this set up, we can call the stylo function, which requires the path that corpus.
> stylo(path = "/path/to/claystylo/")
This will open the Stylo window, and we can make some choices!
We will not need to change anything on the Input & Language menu, as we are working with plain text. On the Features menu, make sure that Start at freq. rank is set to ‘1’. In other uses of Stylo this box can be a good way to study topic modelling looking at less common words (such as the second 100 most frequent words beginning at freq. 100), but for authorship we need the most common.
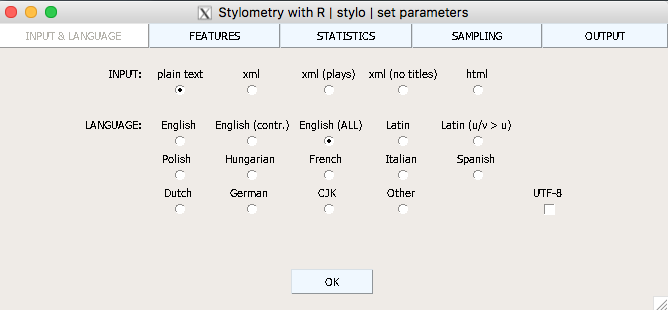
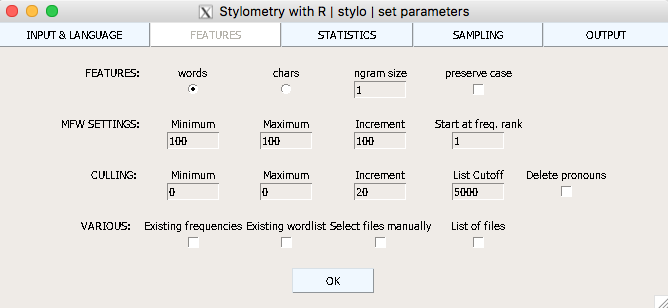
Then in the Statistics menu, we are going to start by choosing PCA (corr.). This is a correlative Principal Component Analysis (add explanation), which will allow us to compare the proximity among the texts in our corpus.
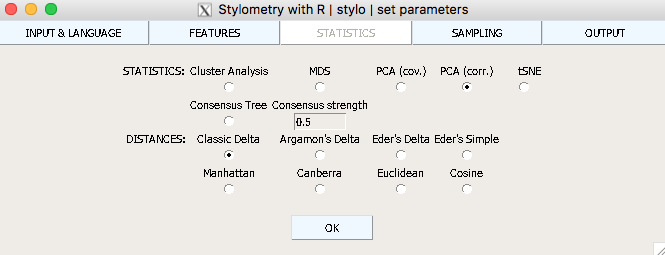
For now we will not use Sampling. On the Output menu, check the pdf and jpg boxes, so that you can preserve your results. Then choose “Both” on PCA/MDS and “Classic” on PCA FLAVOUR. We are ready! Click “OK”.
Let’s look at our Output. The Stylo menu will now close (once you click OK), and you will see RStudio processing the stylo function in your Console.
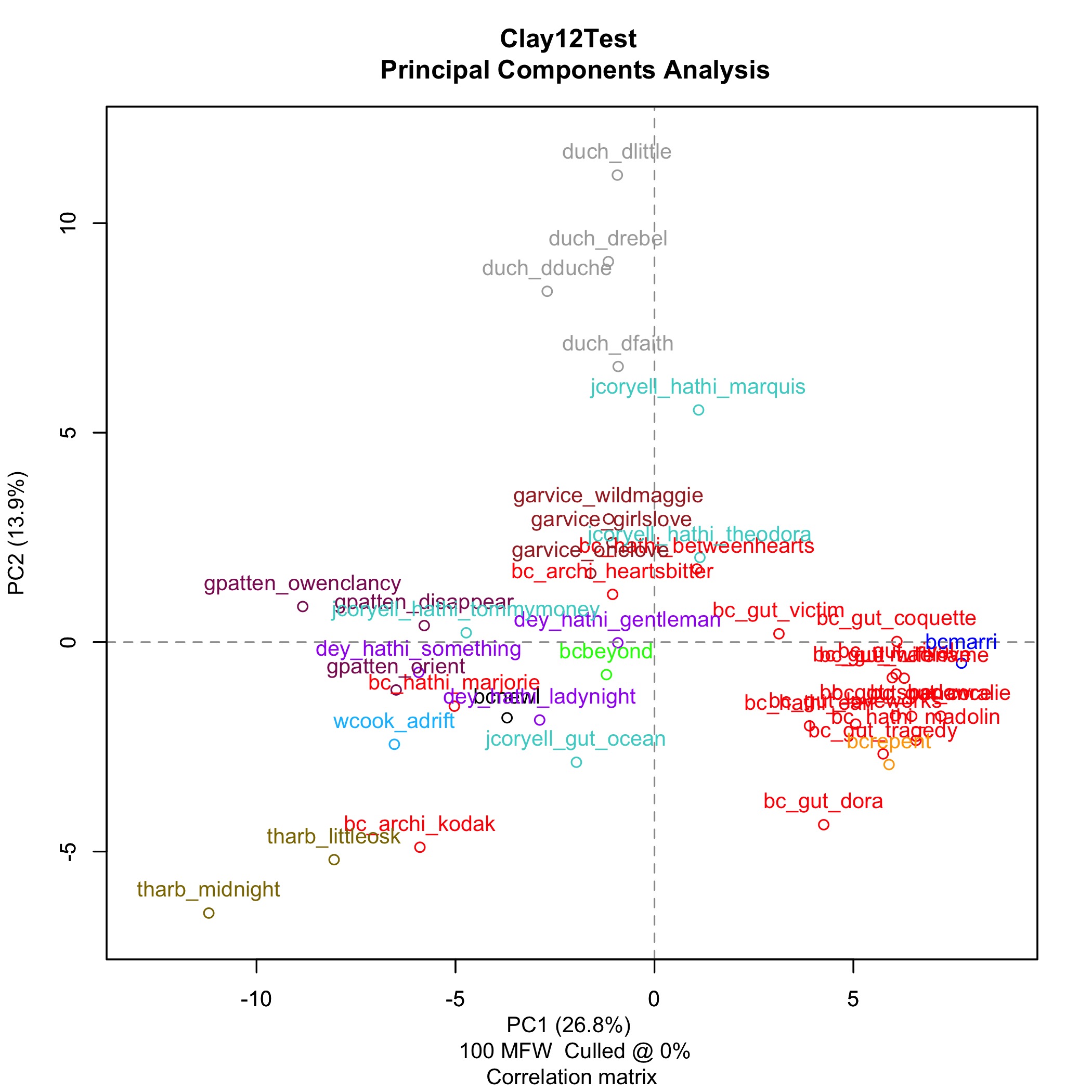
Once it has finished the Stylo function you will see the > arrow return, and the output PCA graph should appear in your Plots window. Let’s look at the output graph and see what it tells us about these different authors, writing under the name Bertha Clay, in the late 19th and early 20th centuries. In this corpus we have works identified as Charlotte Brame, and some identified only as “Bertha Clay”. We have also included control works, works known to have been written by the other authors who often wrote as Bertha Clay, including control works by John Russell Coryell, Charles Garvice, Gilbert Patten, Thomas Chalmers Harbaugh, William Wallace Cook, and Frederic Van Rensselaer Dey. Four works of The Duchess have also been included, which should be visible as distinctly separate from the “Bertha Clay” works, if this graph is actually showing us any indication of authorship.
Results
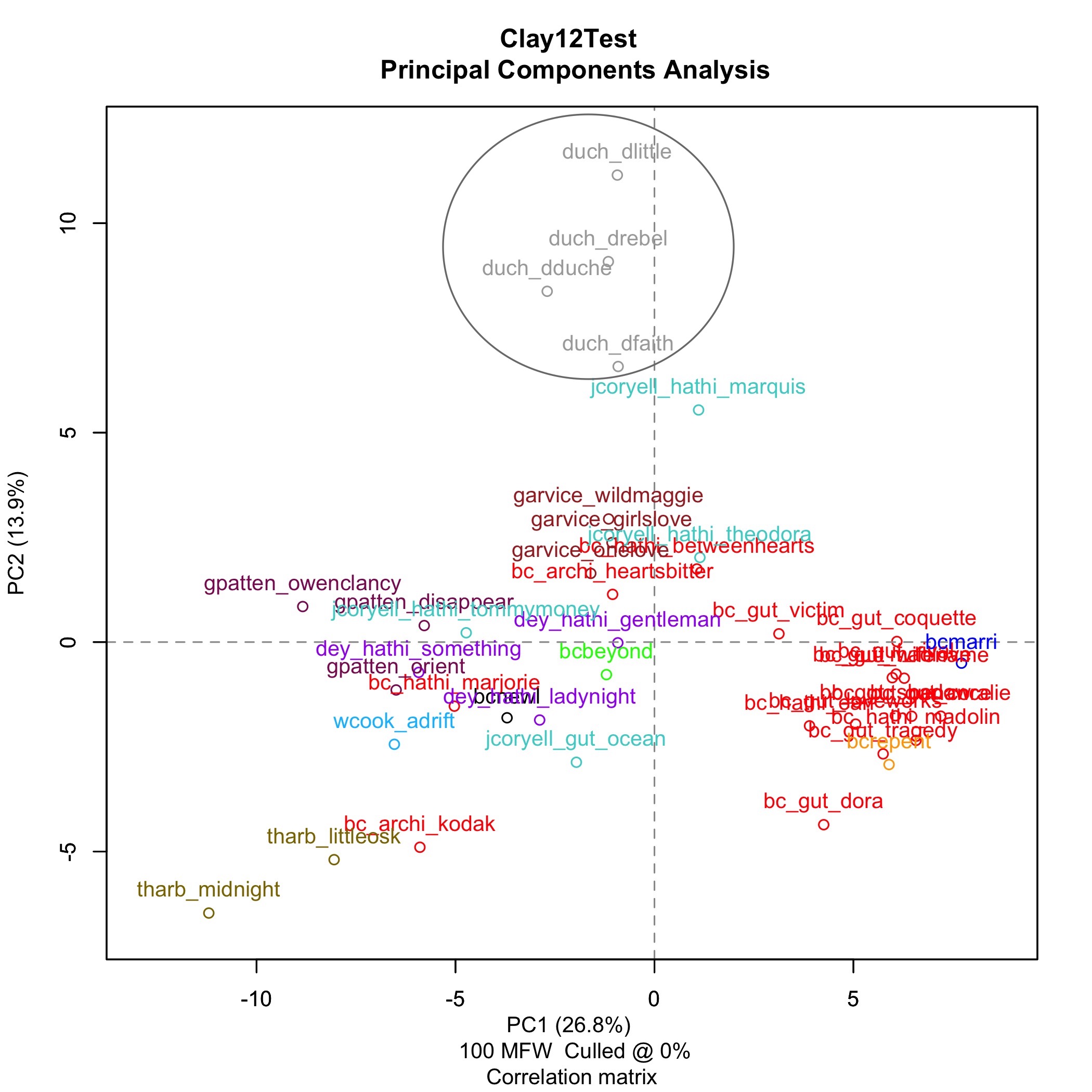
First, we can see the works of the Duchess at the top in Gray. They do appear separate from the other authors.
How do the other known authors compare to Bertha Clay? There is a significant cluster of works all with the author “Bertha Clay”, some identified as Brame on the bottom right of the graph. The other authors are spread to the left of this cluster.
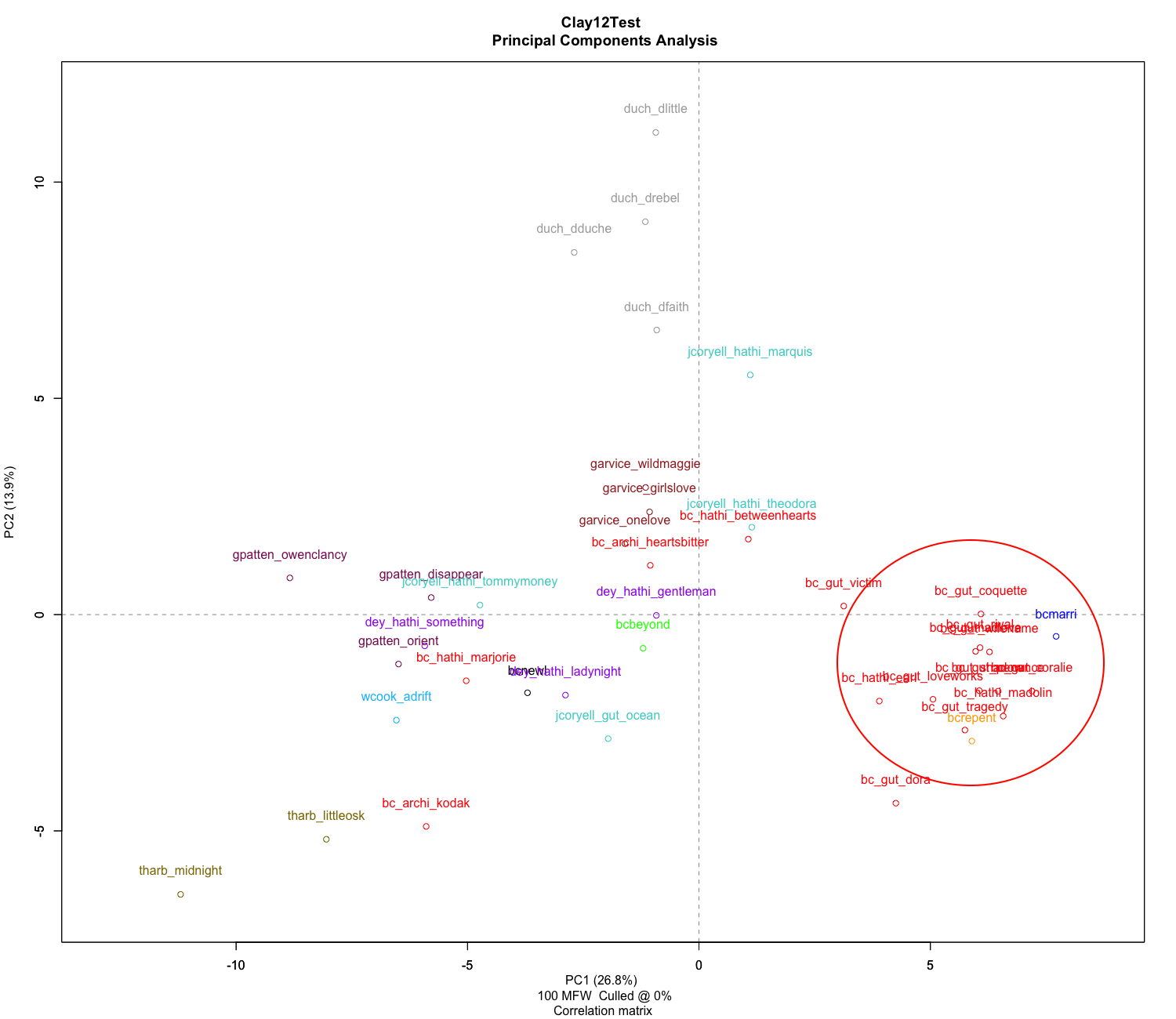
Now, let’s see where the four works of Bertha Clay from the Women Writer’s Genre Fiction Collection land. We find, two are within this cluster, and two seem spread out among the works of the other authors.
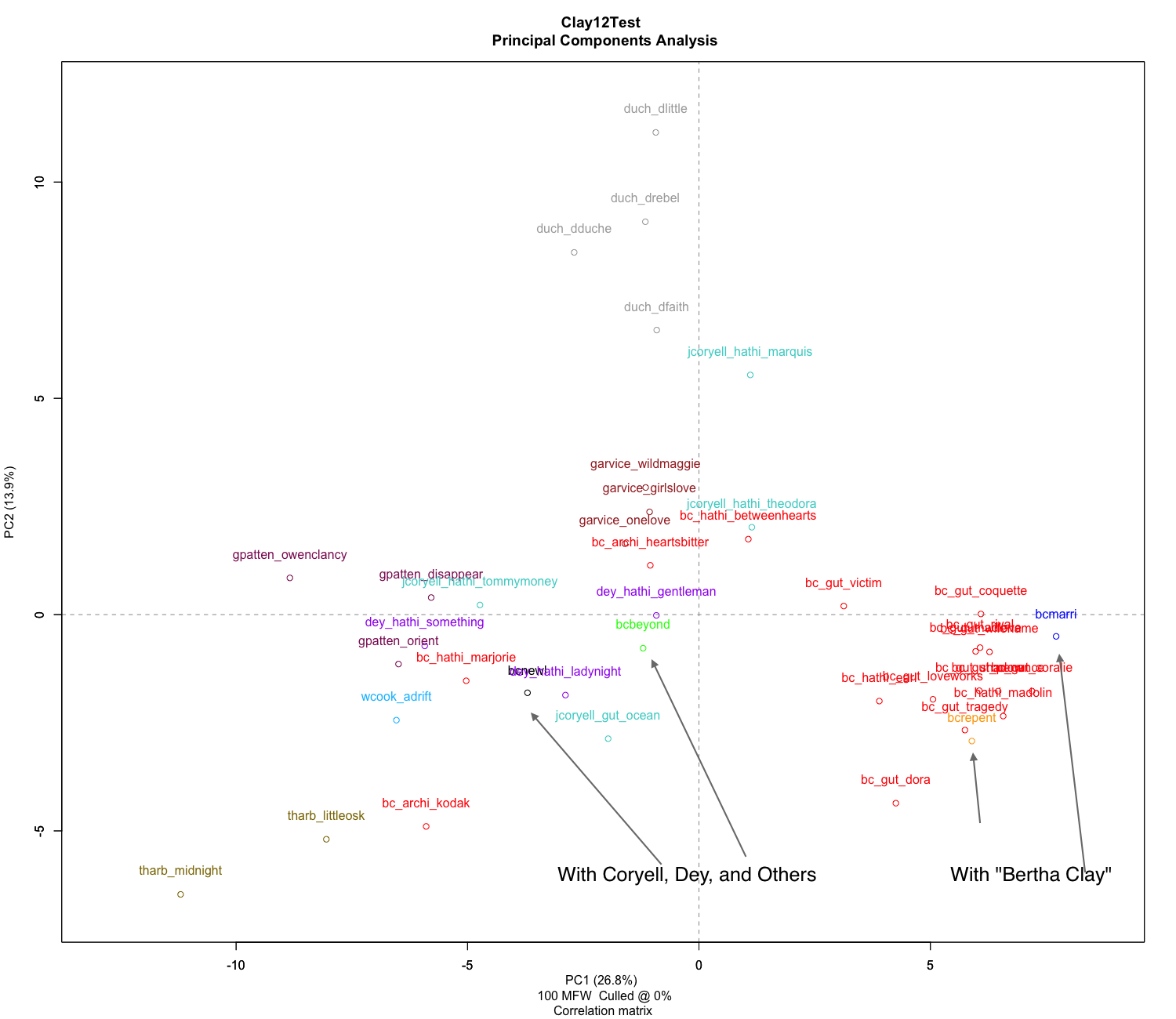 Some of the authors’ works cluster more than others. The Duchess, Garvice, Patten, and Harbaugh show specific clusters. Dey is spread further in the center of the graph of works, and Coryell is spread particularly out among the overall works of the graph. Some works of Bertha Clay are spread among these works, too. The spread of the works of Coryell, throughout the rest of the authors, makes sense in the context of some of his writing.[3] Coryell was known to rework the original texts of other authors in some cases, and that could significantly affect the most common words in his texts.
Some of the authors’ works cluster more than others. The Duchess, Garvice, Patten, and Harbaugh show specific clusters. Dey is spread further in the center of the graph of works, and Coryell is spread particularly out among the overall works of the graph. Some works of Bertha Clay are spread among these works, too. The spread of the works of Coryell, throughout the rest of the authors, makes sense in the context of some of his writing.[3] Coryell was known to rework the original texts of other authors in some cases, and that could significantly affect the most common words in his texts.
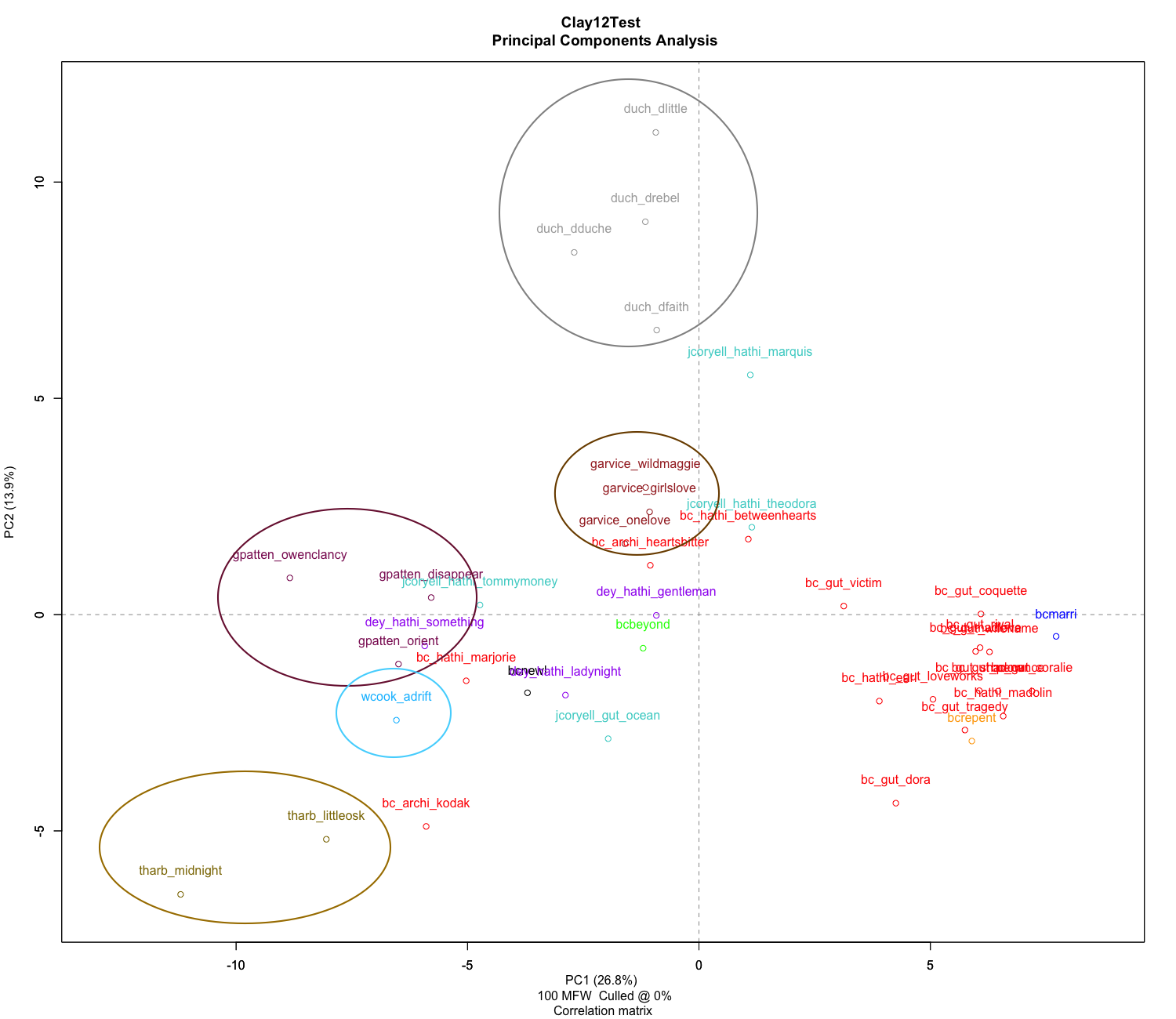
This shows the Women Writer’s works “New Love or Old” and “Beyond Atonement” far from the primary cluster of Bertha Clay. Additionally, The Kodak Woman, Marjorie Deane: a novel, A Heart’s Bitterness, and Between Two Hearts: a novel, from HathiTrust and Archive.org, appear far from the primary cluster.
Analysis
Another way to visualize this data and draw conclusions about the relationships among a corpus of works is through a Cluster Analysis. Let’s do a cluster analysis to our corpus here. First, open stylo again through R studio so that we can make selections about analyzing our corpus:
> stylo(path = "/path/to/claystylo/")
This will open the GUI. The first two menus will remain the same as through our last selection process, as we using “plain text” on INPUT & LANGUAGE and we will Start at frequency rank 1 on FEATURES. On the third tab STATISTICS, however, we are going to choose Cluster Analysis instead of PCA (corr.) so that we can see how our works plot as a tree structure.
Again let’s not use sampling this time, and choose PDF and JPG for output. Click “Okay” to get your graph plotted in the Plots window.
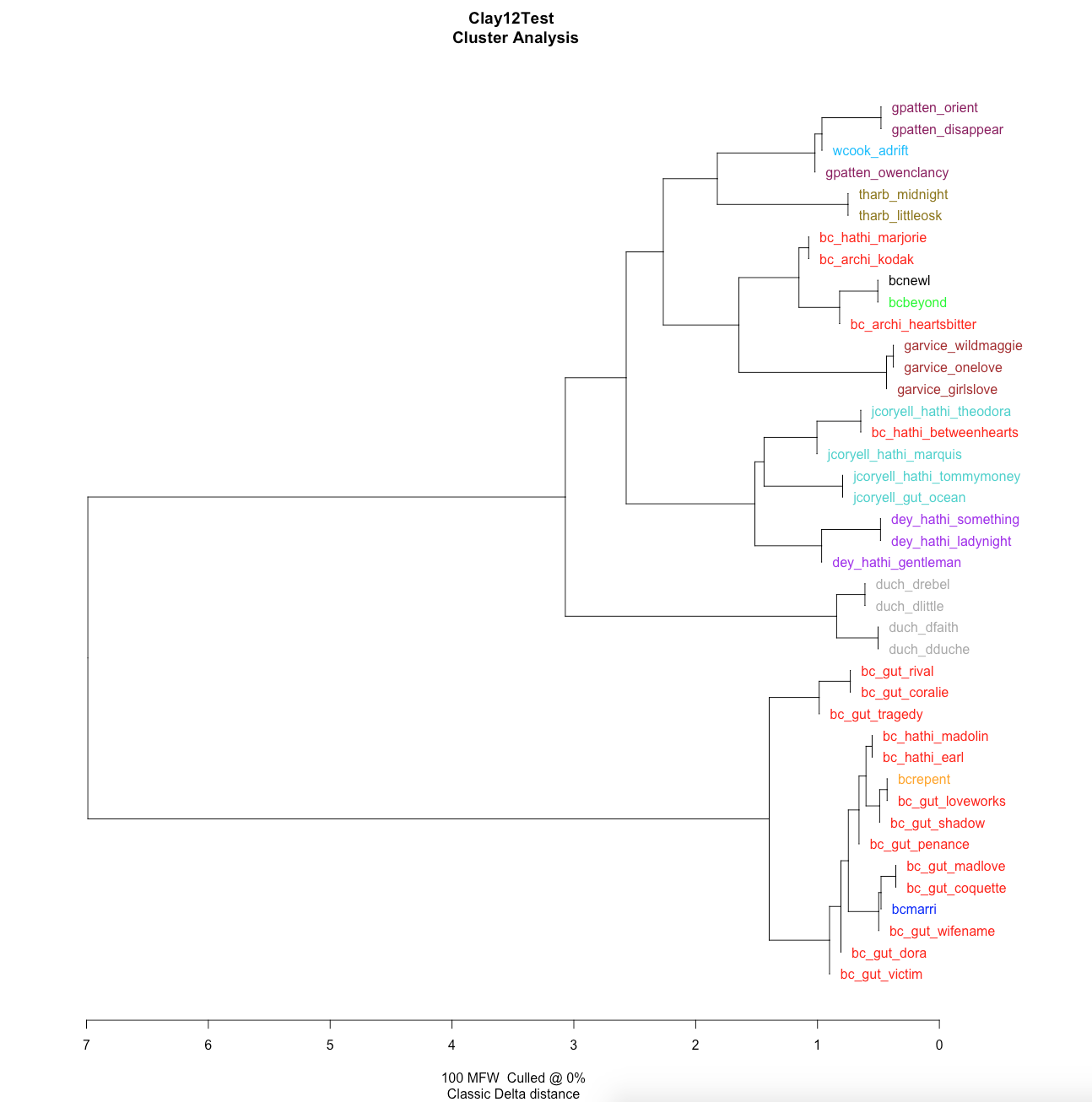 Now what do we have? Because of our naming structure, Stylo helpfully colors the different authors. You can see that Garvice gets his own branch, and Harbaugh, Cook, and Patten show up on branches joined at the top. Coryell and Dey cluster in the middle, with the Bertha Clay novel Between two hearts: a novel among their other identified works. The control works by The Duchess are on a branch at the center of our graph. Finally, a large portion of the Bertha Clay works gain their own much more distinct branch at the bottom of the graph. On this distinct branch, two of the Bertha Clay novels from the Womens Genre Fiction collection appear: Married for her Beauty or, A Bitter Atonement and Repented at Leisure. The two other Bertha Clay novels from the Womens Genre Fiction collection appear amidst the other authors on a branch of unidentified author Bertha Clay novels. These two works, New Love or Old and Beyond Atonement, show up next the Garvice branch and among the other authors’ branches.
Now what do we have? Because of our naming structure, Stylo helpfully colors the different authors. You can see that Garvice gets his own branch, and Harbaugh, Cook, and Patten show up on branches joined at the top. Coryell and Dey cluster in the middle, with the Bertha Clay novel Between two hearts: a novel among their other identified works. The control works by The Duchess are on a branch at the center of our graph. Finally, a large portion of the Bertha Clay works gain their own much more distinct branch at the bottom of the graph. On this distinct branch, two of the Bertha Clay novels from the Womens Genre Fiction collection appear: Married for her Beauty or, A Bitter Atonement and Repented at Leisure. The two other Bertha Clay novels from the Womens Genre Fiction collection appear amidst the other authors on a branch of unidentified author Bertha Clay novels. These two works, New Love or Old and Beyond Atonement, show up next the Garvice branch and among the other authors’ branches.
Conclusions
This analysis appears to show clearly that elements of authorship do show up in PCA and Cluster Analysis graphs. The control works by The Duchess particularly support this. Additionally, distinctive proximity between works by Garvice, works by Patten, and a subset of works by “Bertha Clay” support the distinctive elements of some authors in opposition to Charlotte Brame.
The spread of works by John Coryell also supports our analysis in a search for authorship, as he is known to have rewritten and reworked many stories by other authors, making many of his works closer to co-authored works. Co-authored works would have distinctions among them in these graphs.
Finally, among our set of Bertha Clay novels, two works Married for her Beauty or, A Bitter Atonement and Repented at Leisure show up near the cluster of potential Brame works in both types of graphs, and New Love or Old and Beyond Atonement show up spread among other authors. This type of analysis makes a good jumping off point to do further research into the works that show up as distinct from Brame: Marjorie Deane: a novel, Between two hearts: a novel, A heart’s bitterness, The kodak woman, New Love or Old, and Beyond Atonement.
Footnotes
- Moore, Arlene. 1991. “Searching for Bertha M. Clay.” Dime Novel Round-Up. 10-11. ↑
- Cox, J. Randolph. 2012. “John Russell Coryell Writing as Bertha M. Clay.” Dime Novel Round-Up. 40-41. ↑
- Cox, J. Randolph. 2012. “John Russell Coryell Writing as Bertha M. Clay.” In the Dime Novel Roundup. v. 81, n. 2. 40-41. ↑